
Neural Machine Translation is the latest technology in the world of automated translation, but it still has its limitations, especially when it comes down to more complex languages. We will take a look at some language-specific problems that Asian languages face. The Korean language poses a challenge, in particular, with its varied politeness and formality levels. And one of the ways to resolve honorifics is the context. What impact it could have on the translation industry and how it can be introduced into a machine translation algorithm – we will find out in this article. Furthermore, we are going to discuss these topics and decide for ourselves if the introduction of context-awareness in NMT can help increase the quality of translation and if we can look forward to this improvement for other Asian languages as well.
Linguistic Specifics That Complicate Things
It’s of utmost importance to use the correct honorifics for some languages, such as Korean, Japanese, and Hindi. In Korean, honorifics are used in conversations with elders and people in superior positions. When it comes down to machine translation these honorifics are difficult to address, especially across different languages. There are three types of Korean honorifics – subject, object, and addressee honorification. In English, this is not the case. That makes the translation from English to Korean very challenging.
Politeness and Formality Levels
While the politeness level can be categorized as high, neutral, and low, at the same time the formality could be high or low, which can lead to 6 different ways of expression, depending on the relationship between the people in a conversation, as seen in the graph below.
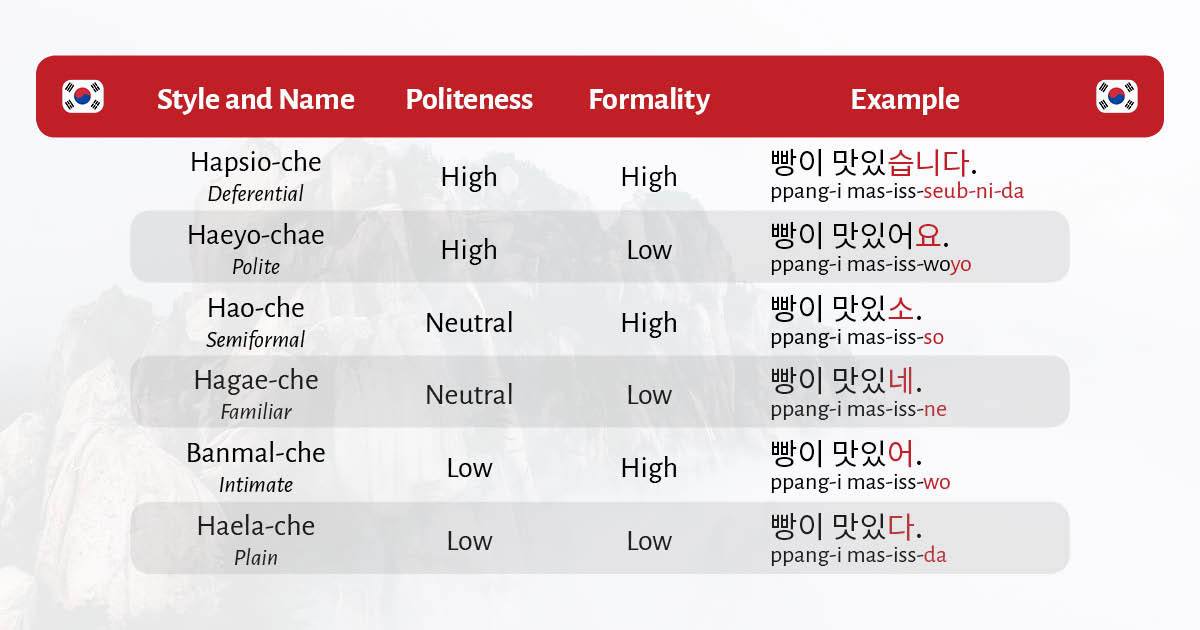
Using the wrong style could lead to humiliation, embarrassment, or even as far as offending the audience. This means that one cannot rely entirely on NMT, especially when it comes down to business and other formal conversations. This is where context-awareness comes into play.
Why Context Matters
Providing context for the translators has always been one of the most important factors when trying to ensure a quality outcome. This can be done in a couple of ways – one is by providing as much information as possible on the given topic, making sure phrases and slang are explained, or even replacing words that could be misinterpreted.
Another good way is to provide visual context, as we know a picture is worth a thousand words. This could be a screenshot that directly points to the place the content would be, which can make the translator’s job that much easier.
In that regard, context-awareness is the next step in the world of machine translation and it has already shown positive results. According to research done in 2021 by the Seoul National University, “the context-aware NMT models can improve not only the translation quality but also the accuracy of honorifics”. And of course, this could be used for other languages that have similar issues with MT.
Introducing Context Into the Algorithm
Context-awareness for NMT can be achieved by adding an honorific-labeled parallel corpus that could signify the relationship between the people in a given conversation. By adding relationship information like son, brother, director – all of these can establish who is the elder, or in a superior position. Even if they are outside the content that is being translated. It will provide much-needed context that will improve the quality and mark the proper honorific levels. In time, and as more data is gathered, context-awareness will become an important part of the machine translation software.
How Does It Work?
Generally, NMT models are operated at the sentence level; it takes an input sentence in a source language and returns an output sentence in a target language. On the other hand, a contextual encoder in NMT is designed to handle one or more contextual sentences as input and extract the contextual representation.
Let’s see how this works in practice:

The examples are taken from the Context-Aware Neural Machine Translation for Korean Honorific Expressions article by Seoul National University. The dialogue is from their dataset, which is extracted from subtitles. The yellow words are verbs that are translated with polite and/or formal honorifics whereas the red words are translated with impolite and/or informal honorifics. The bold keywords are used to determine what types of honorifics should be used. The underlined pronouns indicate that the two utterances are told by the same speaker in (a) and the utterances are formal speech in (b).
Context-Aware Machine Translation for Asian Languages
In general, context is one of the largest problems of machine translation and its quality for most Asian languages. The Korean language is a fine example of this. An introduction to modern and new algorithms is always an opportunity to improve.
Another issue when it comes to machine translation and Asian languages has always been the lack of data. We’ve talked about Korean honorifics, but this could easily be used with similar success with different language-specific problems. Honorifics are used extensively and are an important part of Japanese, Hindi, and Javanese, among other languages. This is definitely a promising advancement in the field and we’re looking forward to its further development.
In summary, the context-aware NMT models can improve not only the translation quality but also the accuracy of honorifics. While their improvements are less significant compared to the honorific-controlled models, they can nevertheless exploit the contextual information to aid in the correct translation of honorifics.